20250421: 什么是向量嵌入
⌛️:2025-04-21 01:37:45
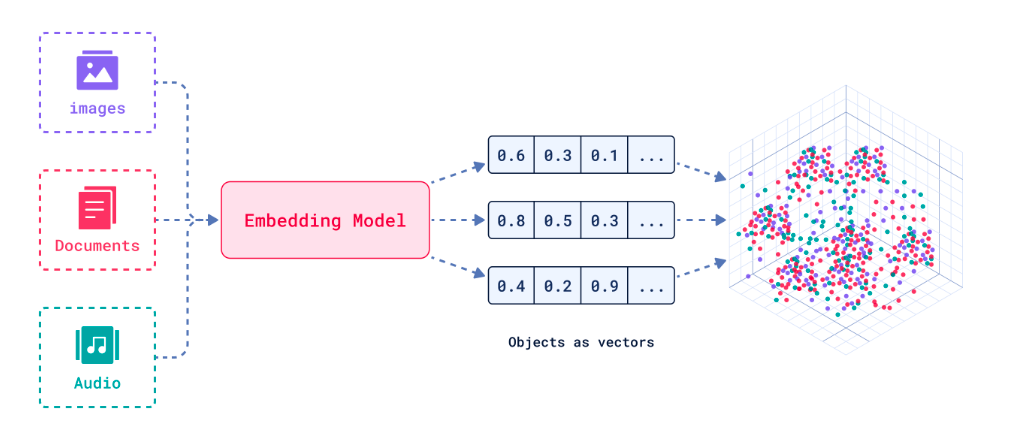
向量嵌入(Vector Embeddings)是讲复杂数据(如文本、图像、音频等)转换为密集数据向量的过程和结果。这些向量通常是高维度的数字数组,使机器能够“理解”数据间的语义关系。
其核心思想是通过数据表示捕捉原始数据的语义信息,讲抽象概念映射到多维空间,这样语义空间的相似性,就可以转化为向量空间中的接近性(数学问题)
向量嵌入工作流程
- 特征提取:从原始数据(文本、图像等)中识别和提取关键特征
- 向量化转换:讲提取的特征通过神经网络映射到高维向量空间
- 维度处理:根据需要进行降维或标准化,优化向量表示
这种机制使计算机能够以数学方式处理和理解复杂的非结构化数据。
向量嵌入的优点(针对数据库场景)
- 稠密表示:相比传统稀疏向量(如 TF-IDF)更节省存储空间
- 相似性保持:原始数据相似性在向量空间得以保留(余弦相似度~语义相似度)
- 跨模态统一:允许文本、图像、视频在同一空间进行联合检索
- 索引友好:适合 HNSW、IVF-PQ 等近似最近邻算法加速
- 增量更新:支持新数据库嵌入无需重建整个向量空间
向量嵌入可能存在的问题(数据库视角)
- 维度膨胀:维度特别多的向量会显著增加存储和内存消耗
- 距离失真:降维处理可能破坏原始空间关系
- 版本漂移:不同模型版本难以建立有效索引结构
- 冷启动:空数据库阶段难以建立有效索引结构
- 精度衰减:量化压缩(如:int8)导致的检索精度损失
核心应用场景
- 混合搜索:结合元数据过滤与向量相似性检索(如语义搜索)
- 内容去重:通过向量距离识别重复、相似内容
- 智能推荐:基于用户行为向量的实体物品匹配(兴趣相似度计算)
- 时序分析:追踪向量漂移模式(用户兴趣、内容热点的演化分析)
- 知识管理:RAG 系统中高效知识检索与上下文关联
- 聚类分析:自动发现数据中的潜在模式和分组结构
- 缓存优化:高频查询结果的向量空间缓存加速
20250417: 什么是向量数据库
2025-04-17 23:50:15
向量数据库(Vector Database)是一种专门设计用于存储、管理和搜索向量嵌入(vector embedding)的数据库系统。
其核心价值在于能够高效执行相似性搜索(similarity search),支持 AI应用中常见的“寻找最相似内容”需求,成为现代人工智能基础设施的重要组成部分。
向量数据库的工作原理
- 向量嵌入存储:将文本、图像等内容通过嵌入模型转换为高维数字向量并存储
- 相似性搜索:使用近似最近邻(ANN)算法实现高效搜索,支持余弦相似度、内积、欧式距离等多种度量方式
- 索引机制:通过 HNSW(分层可导航小世界图)实现快速导航,或 IVF(反向文件索引)进行聚类加速
- 元数据过滤:支持在相似性搜索中结合传统数据库的过滤条件(如时间范围、类别标签)
这种设计使向量数据库能在毫秒级内从百万级甚至数十亿向量中找最相似项。
向量数据库的优势
- 高效相似性搜索:通过 ANN 算法实现 O(log n)时间复杂度,比传统数据库的精确搜索 O(n)快很多
- 混合查询能力:可同时处理“找到与这张图片相似且价格低于100元的产品”这类复合查询
- AI应用集成:特别适合实现 RAG架构中长期记忆模块
- 规模可扩展性:支持海量向量数据的存储和检索
- 多模态支持:同时处理文本、图像、音频等不同类型的嵌入向量
- 实时性能:支持高并发、低延迟的查询操作
向量数据库可能存在的挑战
- 精度与速度权衡:更高精度通常意味着更慢的查询速度
- 资源消耗:高维向量索引可能需要大量内存
- 嵌入质量依赖:搜索结果质量很大程度上取决于输入嵌入的质量
- 维度诅咒:随着向量维度增加,搜索效率可能下降
- 复杂调优需求:最佳性能可能需要专业知识进行参数调优
常见向量数据库
向量数据库 VS 传统数据库
| 维度 | 向量数据库 | 传统关系型数据库 |
|---|---|---|
| 数据类型 | 高维向量(非结构化数据特征) | 标量(数值、字符串等结构化数据) |
| 查询方式 | 近似最近邻(ANN)、语义相似性匹配 | 精确匹配(SQL条件查询) |
| 应用场景 | 推荐系统、图像检索、RAG、生物信息学 | 事务处理、报表生成 |
| 扩展性 | 水平扩展支持十亿级向量 | 垂直扩展为主,单表容量有限 |
- 扩展:什么是向量
- 向量(Vector)是数学和物理学中的基本概念,指同时具有**大小(模长)**和**方向**的量,可形象化为带箭头的线段。例如,位移、速度、力等物理量均为向量
- 数学表示:在坐标系中,向量可用坐标形式表示(如二维平面中的(2,3)),或通过起点和终点(如向量AB)描述
- 运算规则:包括加法(平行四边形法则)、减法、数乘、点积(内积)和叉积(外积),适用于物理和工程中的合力分析、投影计算等场景
- 抽象化扩展:在线性代数中,向量被抽象为向量空间的元素,可能不局限于几何意义上的方向,而是满足特定运算规则的数学对象
- 简言之:向量是描述多维特征的基础数学工具,而向量数据库则是AI时代处理非结构化数据的核心技术
- 向量(Vector)是数学和物理学中的基本概念,指同时具有**大小(模长)**和**方向**的量,可形象化为带箭头的线段。例如,位移、速度、力等物理量均为向量
20250416: 什么是多模态模型
2025-04-16 23:14:36
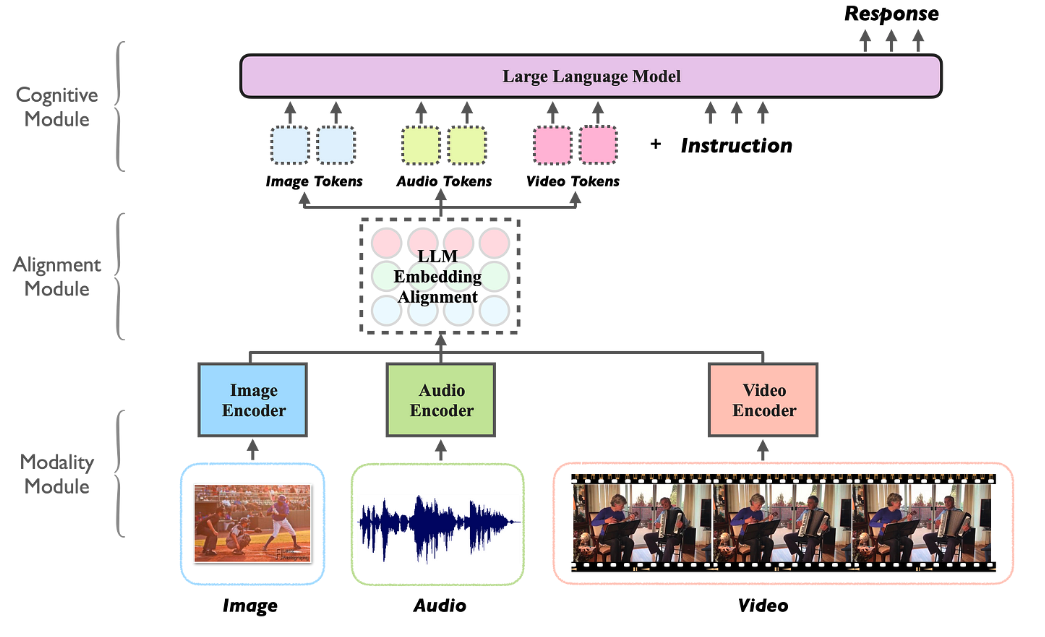
核心工作原理(多模态模型的工作机制包含三个关键阶段):
- 模态编码:使用专用编码器(CNN/ViT 处理图像、BERT 处理文本等)提取各模态特征
- 特征对齐:通过交叉注意力机制(cross-attention)建立细粒度跨模态关联(如图像区域与文本描述的对应关系)
- 联合推理:在共享表示空间中进行跨模态信息融合与语义推理
技术优势(系统实现角度)
- 统一接口:支持自然语言作为跨模态交互的统一接口
- 知识迁移:视觉-语言等跨模态知识的相互增强
- 上下文扩展:能同时利用多模态上下文信息(如文本描述+示意图)
- 数据效率:通过多任务学习提升小样本场景表现
- 灵活部署:架构灵活性,支持级联式(冻结编码器+可训练适配器)或端到端联合训练架构(不同模态流程整合到单一神经网络中的架构)
实现挑战(工程化角度)
- 计算复杂度:多模态并行处理带来的显存/算力压力
- 对齐噪声:跨模态数据标注的噪声会影响注意力机制
- 模态鸿沟:不同模态特征分布的差异导致融合困难
- 延迟积累:级联架构中各组件(如图像编码器+LLM)的推理延迟叠加问题
- 评估困境:现有基准(如 MMLU、MMBENCH)难以全面评估跨模态推理能力
20250415: 什么是大模型量化
2025-04-15 01:43:53
量化(Quantization)是一种通过降低模型参数的数值精度来压缩模型大小的技术。在深度学习中,模型的参数通过以32位浮点数(FP32)来存储,通过量化可以将其转换成更低精度的表示形式,从而减少模型的内存占用和计算开销。
FP32的大小是4字节(每个字节8bit, 4字节* 8bit =32 bit)而 FP16的大小是2字节,则为16bit.
这也是为什么大家喜欢用 Q4量化模型的原因,跟 FP16(16bit)的模型相比,Q4(4bit)的模型只有1/4的大小,运行起来需要的内存也是1/4.
现在大多数模型训练都采用 FP16的精度,而当下流行的Deepseek-V3采用了 FP8精度训练,能显著提升训练速度和降低硬件成本。
Q4_K_M 是什么意思
这种命名方式一般是 GGUF&GGML 格式的模型,它们通常采用 K量化模型,格式类似 Q4_K_M,这里的 Q 的后面数字代表量化精度,K代表 K量化方法,M代表名在尺寸和 PPL(Perplexity,困惑度)之间的平衡度,有0, 1,XS, S, M, L 等
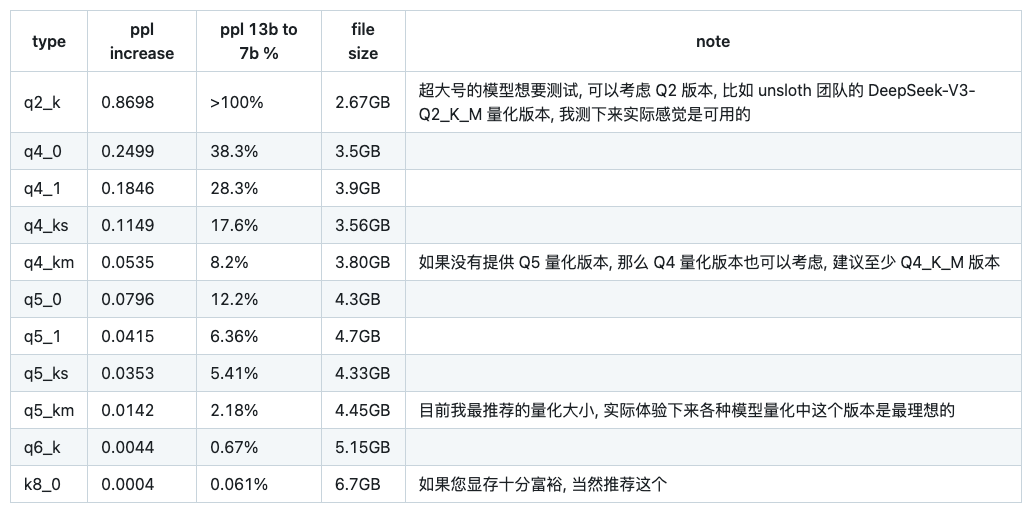
PPL 是评估语言模型性能的重要指标,它用来衡量模型对下一个词的预测准确程度。常见 Kl量化版本的 PPL 对比(这是一个7B 模型)
bf16、4bit、int4、fp8是什么意思
- bf16是16bit 的精度,4bit 是4bit 精度,同样也建议至少使用4bit 量化的模型,除非模型特别大200B+
20250414: 什么是 LLM蒸馏技术
2025-04-14 00:25:15
LLM 蒸馏(Distillation)是一种技术,用于将大语言模型(LLM)的知识转移到较小的模型中。其主要目的是在保持模型性能的同时,减少模型的大小和计算资源需求。通过蒸馏技术,较小的模型可以在推理时更高效地运行,适用于资源受限的环境。
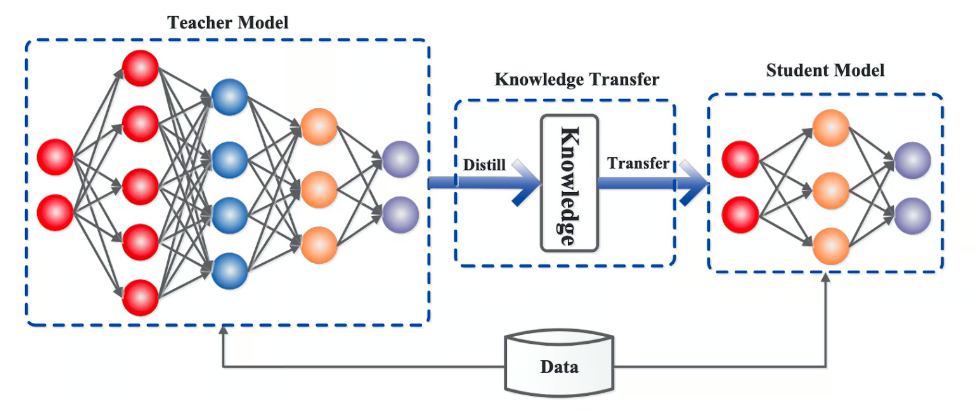
蒸馏过程(步骤)
训练教师模型:首先训练一个大型且性能优越的教师模型。
生成软标签:使用教师模型对训练数据进行预测,生成软目标(soft targets),这些目标包含了教师模型的概率分布信息。
训练学生模型:使用软目标和原始训练数据(hard targets)来训练较小的学生模型,使其能够模仿教师模型的行为。这种方法不仅可以提高模型的效率,还可以在某些情况下提高模型的泛化能力。
蒸馏的优点
减少模型大小和计算资源需求
增加推理速度、易于访问和部署
蒸馏可能存在的问题
信息丢失:由于学生模型比教师模型小,可能无法完全捕捉教师模型的所有知识和细节,导致信息丢失。
依赖教师模型:学生模型的性能高度依赖于教师模型的质量,如果教师模型本身存在偏差或错误,学生模型可能会继承这些问题。
适用性限制:蒸馏技术可能不适用于所有类型的模型或任务,尤其是那些需要高精度和复杂推理的任务。
典型例子
GPT-4o(教师模型)中提炼出 GPT-4o-minio(学生模型)
Deepseek-R1(教师模型)中提炼出 Deepseek-R1-Distill-Qwen-32B(学生模型):这个不是传统意义上的蒸馏,是蒸馏+数据增强+微调
其他蒸馏技术
数据增强:使用教师模型生成额外的训练数据。通过创建更大、更具包容性的数据集,学生模型可以接触到更广泛的场景和示例,从而提高其泛化性能。
中间层蒸馏:将知识从教师模型的中间层转移到学生模型。通过学习这些中间表示,学生模型可以捕获更详细和结构化的信息,从而获得更好的整体表现。
多教师蒸馏:通过汇总不同教师模型的知识,学生模型可以实现更全面的理解并提高稳健性,因为它整合了不同的观点和见解。

